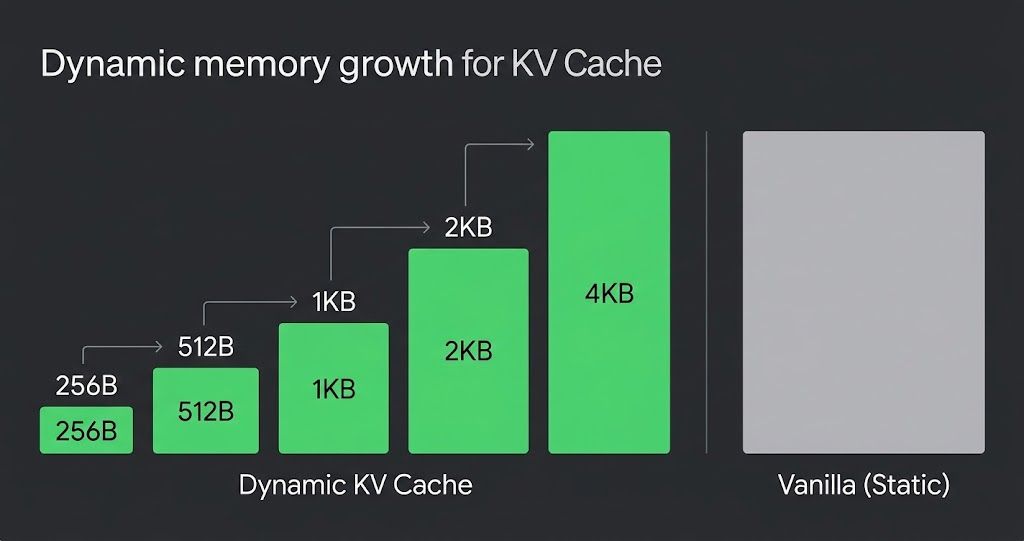
Dynamic KV Cache Resize in llama.cpp — 8 GB Savings on a 27B Model
Start with 16 MB and grow on demand. An experimental llama.cpp patch that reduced upfront KV allocation and avoided GPU OOM on Apple Silicon.
Start with 16 MB and grow on demand. An experimental llama.cpp patch that reduced upfront KV allocation and avoided GPU OOM on Apple Silicon.
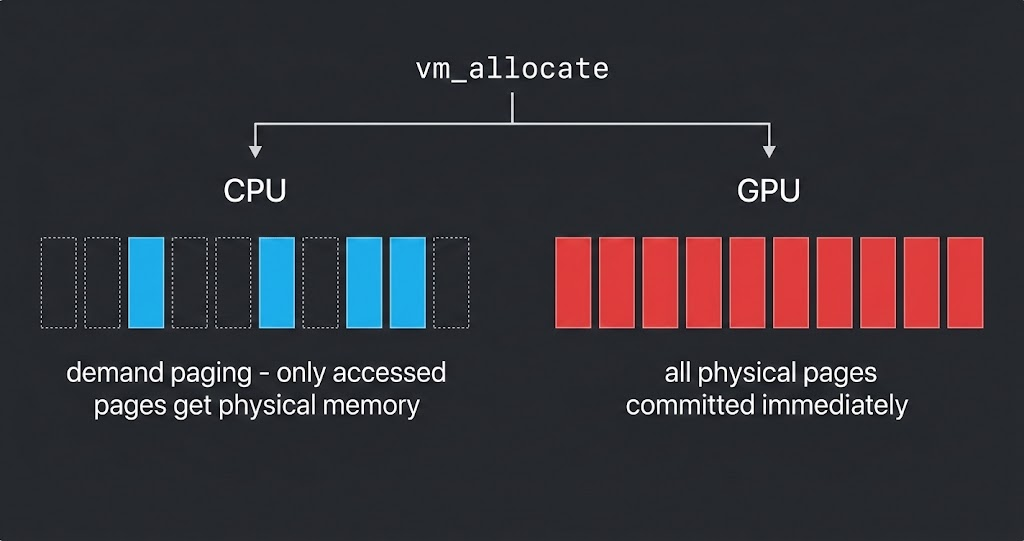
I tried to use macOS demand paging to save GPU memory in llama.cpp. It didn't work — and understanding why led to a better approach.
A technical analysis of llama.cpp's KV cache architecture, the llama_memory_i interface, and how PagedAttention can be implemented as a composable new memory strategy.
What happens when you hold GPU load constant and only increase memory pressure? I designed an experiment to isolate swap-induced slowdown from GPU contention on a 32GB Mac Mini.
Sweeping parallelism from 1 to 10 concurrent requests on a 30B model to find exactly where performance falls off a cliff — and why KV cache pre-allocation is the culprit.
Switching ollacode's system prompt from Korean to English and measuring real performance gains with ollama-bench. 60% faster TTFT, 55% fewer input tokens.
I built ollama-bench to measure local LLM performance degradation — token generation speed, prefill speed, TTFT, and memory usage over progressive requests.
Day 2 of ollacode development — optimizing token usage for local LLMs with English prompts, context compaction, and smart history management.
Day 1 of building ollacode — a lightweight CLI coding assistant powered by Ollama's qwen3-coder:30b model with Telegram bot integration.

Key findings from OpenZeppelin's audit of the EIP-4337 Account Abstraction implementation — deposit manipulation, silent token transfer failures, and the dangers of Solidity's transfer().